Gen-AI dans la narration audio : à quoi ça sert ?
22 juillet 2024
La sortie de ChatGPT fin 2022 a fait exploser le voile sur l'IA générative pour le grand public, mais son utilisation pour le contenu, en particulier la production audio, s'apparente à une mijoteuse depuis de nombreuses années et pourrait nécessiter plus de temps avant qu'elle puisse être diffusée plus largement.
Du département Technologie et Innovation de l'UER, le chef de projet principal Ben Poor partage ses réflexions.
Bien que je ne sois pas étranger au monde de l'IA générative, je ne peux pas prétendre être un expert. Dans le monde de la R&D, je me suis toujours concentré sur la D plutôt que sur la R&D, sur la meilleure façon de mettre en œuvre et d'appliquer les nouvelles technologies.
Les lecteurs connaissent peut-être le projet EuroVOX de l'UER, qui a une motivation similaire : adapter l'évolution des outils linguistiques basés sur l'IA au service des producteurs de contenu dans le cadre de leurs flux de travail quotidiens.
Bien que de nombreux collègues se trouvent dans une situation similaire, mon point de vue porte davantage sur la radio et l'audio. Ainsi, lorsqu'on m'a demandé de parler de l'IA générative au 50e EBU Audio Storytelling Festival (héritier de l'International Features Conference), c'était l'occasion d'aborder le sujet plus largement.
La mission était de prédire l'impact que l'IA pourrait avoir sur la narration audio et de discuter des opportunités, même si elle est déjà en train de devenir courante. Une vague d'IA a déferlé sur le secteur en 2023, et tout porte à croire qu'elle se poursuivra en 2024 et au-delà.
ChatGPT a ancré les grands modèles linguistiques (LLM) dans la conscience publique. Il s’agit d’ensembles de données (modèles) construits en aspirant de vastes océans de contenu textuel accessible au public (par exemple, des sites Web, des forums, des documents) et exécutés via un processus capable d’apprendre les relations statistiques entre les mots. Avec suffisamment de données et les bonnes instructions, ce processus peut ensuite générer du texte bien structuré, comme nous le voyons dans ChatGPT.
Les mêmes techniques peuvent être appliquées aux images et à l'audio.
Très simplement, avec une formation sur suffisamment de contenu et des conseils sur les caractéristiques et les paramètres de ce contenu, il est possible de créer de grands modèles pour l'audio, les images et même la vidéo.
En effet, la dernière version du modèle GPT qui sous-tend ChatGPT est considérée comme « multimodale », car elle peut comprendre le texte et les images.
GPT en est actuellement à sa quatrième itération depuis sa création en 2018, mais l'explosion de l'intérêt et de l'utilisation peut être attribuée au fait que celui-ci et d'autres modèles sont plus facilement accessibles, ce qui a donné naissance à un écosystème dynamique d'expérimentation et d'innovation.
C'est pourquoi le point de départ de ma présentation était d’examiner les dernières nouveautés dans le monde de « l’IA génératrice de consommateurs » et comment nous pouvons l’appliquer utilement à la narration audio.
Pour raconter cette histoire, j’avais besoin d’un sujet sympathique, j’ai donc choisi l’une de mes deux boxeuses, Nelly, qui est aveugle. Il y a deux ans, nous l'avons adoptée auprès d'une association de sauvetage, où elle avait été abandonnée à cause de son handicap.
Je voulais planter le décor en racontant son histoire d'origine et comment elle avait trouvé un foyer heureux avec notre famille. De retour récemment d'un voyage qui comprenait sa première expérience à la plage (qu'elle a adorée), j'ai décidé d'inclure ce détail, et le fait qu'elle a entièrement pris possession de mon canapé (comme c'est inévitable avec les chiens Boxer).
Pour générer l'histoire, je me suis tourné vers la dernière version de ChatGPT, en utilisant certaines techniques d'incitation intelligentes que j'avais apprises lors d'un récent cours de l'EBU Academy dirigé par l'étonnant Mark Egan dans le cadre de leur School of AI.
Mon invite était :
Écrivez-moi une histoire en 3 parties sur 9 paragraphes, détaillant les aventures d'une chienne Boxer appelée Nelly. Elle a 6 ans et a été adoptée par une famille qui voulait un ami pour leur autre chien, appelé Popcorn. Nelly est aveugle et allait être euthanasiée avant d'être adoptée par sa nouvelle famille. Nelly aime dormir, manger et jouer avec son nouvel ami Popcorn. Elle adore rencontrer de nouvelles personnes et, lorsqu'elle est heureuse, elle remue ses fesses en faisant sa danse spéciale.
La première partie de l'histoire devrait parler de son début de nouvelle vie avec sa nouvelle famille adoptive et de certaines de ses premières réactions à l'idée de se retrouver dans un nouveau foyer. Il faudrait parler de certains des défis auxquels elle est confrontée en raison de sa cécité et du fait qu'elle se cogne souvent contre des objets.
La deuxième partie de l'histoire devrait parler du jour où elle est allée à la plage et où, pour la première fois, elle s'est sentie libre de courir et de sauter dans les airs. Elle était très heureuse et s'est bien amusée à creuser dans le sable.
La troisième partie de l'histoire devrait parler d'elle étant heureuse, dormant sur le canapé. Elle est fatiguée après avoir tant couru sur la plage mais ronfle joyeusement à côté de sa famille. Elle rêve d'être à nouveau sur la plage.
Les résultats sont impressionnants en termes de structure, mais ne constituent pas vraiment un chef-d'œuvre créatif. Il a également supposé à tort que mon autre chien était un labrador. Ces résultats ne sont pas surprenants, et la base statistique de la génération donne l’impression qu’ils sont un peu… moyens. Il est également trop habile pour compléter les informations manquantes, halluciner et être « assurément incorrect ».
Maintenant que j'avais mon histoire, j'avais besoin de l'audio, alors je me suis tourné vers quelque chose de plus familier : le clonage de voix.
L'un des aspects d'EuroVOX est que nous sommes capables de prendre un clip audio avec plusieurs intervenants et de les faire parler efficacement dans des langues différentes. Cela fait appel à plusieurs processus, notamment la transcription, la traduction et la synthèse vocale, ainsi qu'à la prise dynamique des modèles vocaux des locuteurs lors de la synthèse des phrases traduites.
Dans ce cas, j'ai cloné les modèles de parole de mon collègue, le Dr David Wood, ce qui a produit des résultats tout à fait remarquables qui correspondaient parfaitement au contenu. Je crois sincèrement qu'il pourrait avoir une carrière prospère en tant que doubleur pour les livres pour enfants.
La dernière étape consistait à ajouter une production audio sous forme de musique d'introduction et d'interchapitre. Lalya Gaye, de l’Initiative IA et données de l’UER, m’a orienté vers une multitude de ressources pour la génération de musique par l’IA. Je ne savais pas que la technologie était si mature, mais en utilisant des outils comme Udio et Suno, j'ai pu générer de la musique réaliste dans différentes langues et styles, avec des paroles qui racontaient l'histoire.
J'ai ensuite construit une présentation en utilisant un outil qui crée des diapositives PowerPoint à partir d'invites, décrivant le processus et incluant des ressources d'image, encore une fois en utilisant l'IA générative.
Pas un mauvais après-midi de travail.
En fin de compte, ma présentation s'est bien déroulée (regardez la vidéo ici), même si le visionnage des autres soumissions soignées m'a fait comprendre que le processus de narration est loin d'être un calcul mathématique.
Quand j'ai eu fini, un membre inquiet du public a demandé : « Tout cela ne va-t-il pas nous faire perdre notre emploi ? » Je regrette que ma réponse impromptue n’ait pas été convaincante, mais la vérité est que je ne crois sincèrement pas que ce sera le cas.
Ce que j’ai mis au point était peut-être un bon premier jet, un carnet de croquis, comme c’est la façon dont ces techniques sont utilisées depuis longtemps. En demandant à un modèle de générer quelques premières idées, cela peut être utile comme point de départ pour un processus créatif plus raffiné qu'un humain poursuivra. Les voix de synthèse peuvent être très convaincantes, et permettre à chacun de mettre une voix sur son texte peut être inestimable, car l'entendre avant d'entrer dans le studio peut faire gagner du temps et de l'argent.
Mais ces outils ne peuvent pas encore remplacer l'art de raconter des histoires.
En guise de conclusion, je tire certains enseignements de mes expériences en utilisant des techniques similaires pour automatiser la production de bulletins d'information multilingues, ce qui pourrait être utilisé pour les enceintes intelligentes et les voitures connectées.
La principale différence est qu'il ne s'agit pas de générer l'histoire à partir de zéro, mais plutôt d'utiliser la plateforme News Pilot de l'UER pour regrouper et synthétiser des résumés basés sur des informations réelles fournies et vérifiées par les membres de l'UER. Le fait que cela puisse ensuite être exprimé de manière synthétique dans des dizaines de langues en quelques minutes pourrait être précieux pour aider nos membres à atteindre de nouvelles plateformes sans avoir à investir des ressources importantes.
Liens et documents pertinents
Ecrit par

Related news
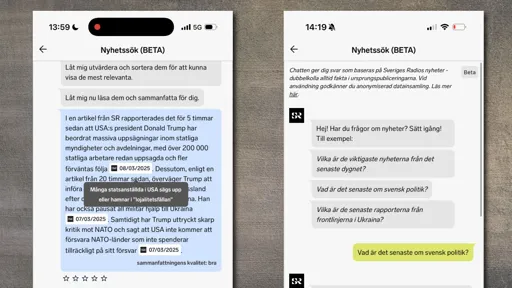
Sveriges Radio and EBU collaborate on a smarter way to search the news
Since March 2025, Svergies Radio (SR) listeners have been testing a new type of news search in the form of an AI-driven chatbot powered by Neo from the...
Oh smart! Strengthening collaboration on open-source software for media
OSMART is an initiative that has seen several organizations active in the media delivery ecosystem collaborating to raise awareness of the tools they provide....

Histoires
Questions-réponses avec Anne Lagercrantz : « La responsabilité est si précieuse, car elle deviendra une denrée rare »
Nous nous entretenons avec Anne Lagercrantz, directrice générale de la télévision suédoise SVT, dans le cadre d'une série d'entretiens avec les contributeurs...

Histoires
Questions-réponses avec Pattie Maes : « Nous n’avons pas besoin de tout simplifier pour tout le monde »
Nous nous entretenons avec Pattie Maes, professeure d'arts et de sciences médiatiques au MIT Media Lab, dans le cadre d'une série d'entretiens avec les...

Histoires
Questions-réponses avec Peter Archer : « Ce que l’IA ne change pas, c’est qui nous sommes et ce que nous sommes censés faire. »
Nous nous entretenons avec Peter Archer, directeur du programme IA générative à la BBC, dans le cadre d'une série d'entretiens avec les contributeurs du...

Histoires
User interaction, accuracy and value-added services key AI innovation drivers at PSM, DTS 2025 shows
With the emergence of AI technologies, most media organizations have made it a strategic priority to innovate around their data, as this year's EBU Data...
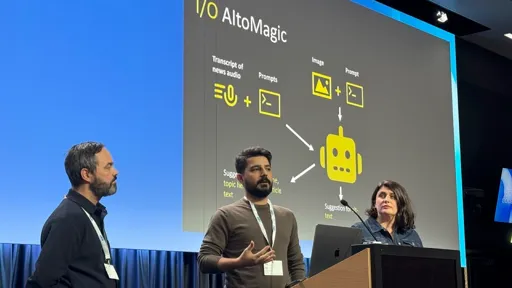
Widespread innovation on AI tools across public service media
An EBU workshop showcased a variety of projects from across the EBU membership, ranging from the use of LLMs to assist content creation or improve audience...

Blogs
Assurer l’avenir des médias de service public : les principales stratégies des médias sociaux pour 2025
Pour 2025, les stratégies des médias sociaux des médias de service public doivent s'articuler autour de deux objectifs clés : impliquer les jeunes générations...